デジタル技術の分野で成功するためには、質の高いデータ基盤が重要なのと同様に、貴組織のデータ資産をつなぐ基底にある構造も重要です。 人工知能、機械学習、R&D組織を変革するためのその他のデジタルビジネスアプリケーションでは、高品質のデータと効果的なデータモデルから出発することが不可欠です。
貴社のデータが編成、保存され、その中のデータ関係がデータモデルによって定義される方法 効果的なモデルは、組織全体のユーザーがビジネスの運営方法を簡単に理解できるようにします。 これは、個人的なビジネスライン(LOB)や組織内の業務の境界を越えて適用された場合に、最大の価値を実現する、ほとんどすべての価値の高いビジネスソリューションにおける要です。 このデータモデルは、将来のビジネスクリティカルなプロジェクトの成功にあたり、情報管理の戦略的な柱となるものです。
しかし、現代のデータは非常に複雑で多様化しており、データモデルを作成する作業はさほど簡単ではありません。 研究開発企業にとっては、科学データが独自で複雑であり、しばしば切断されるため、これは特に扱いにくいものでしょう。 さらに、生産されるデータの量が指数関数的に増加するにつれて、新しいデジタル技術を成功裏に実装するための基礎として有効なデータモデルを作成することはこれまでにないほど重要になっています。
弊社の最新のホワイトペーパーでは、急速に変化するデジタル環境に関連する問題を調査し、変化に応じたデータ基盤を準備する方法を検討しています。 このブログ記事は、データモデリングの利点を説明し、一般的な落とし穴を概説し、効果的なデータモデルがどのように見えるかについての研究開発例を示しています。
研究開発組織がデータモデリングから利益を得る方法
データモデルは、貴組織内のデータを定義および分析するための標準的なメカニズムを提供します。 しかし、更なる使い方もあります。 実際、優れたデータモデルなら、適切に設計されたデータ構造を組み合わせることで、貴組織内のすべてのスタッフが(収集されていたことさえ知らなかった)情報に効率的にアクセスし消費できるようになるため、戦略的優位をもたらすものになります。
さらに、効果的な企業データモデルでは、多くの大規模な研究開発企業が互いに通信しないさまざまなシステムに独自にデータを格納しているため、組織の既存の情報システムを統合することができます。 これらの各システムのデータをモデリングすることで、関係や重複を確認し、相違を解決し、そして異なるシステムを統合することによりこれらを連携させることができます。 この統合された企業データモデルは、データクエリーやレポーティングにおいて、一貫して状況に合った情報をはじめ、データ系統、そして一元化された情報をもたらします。
最後に、よく考えられたデータモデルを使用すると、モデリングプロセスでチームがデータを定義する必要があるため、ビジネス領域の深い洞察が得られます。 データモデルに現れるデータと関係は、ビジネスプロセスの理解を構築するための基礎を提供します。 これは、何の抵抗もない新規参加や社外データと社内データの融合を可能にし、貴社のビジネスの挑戦やチャンスをナビゲートする手助けとなる解析や予測の価値を高めます。
一般的なデータモデリングの落とし穴を避けるためのヒント
初めに、具体的な目標があることを確認します。 モデル開発のためのビジネス利用ケースが明確に定義されていない場合、データモデルは最適な価値を提供しません。 従って、データモデリングプログラムで達成しようとしていることを慎重に考え、特定のビジネスニーズやプロセスの改善に集中するようにしましょう。
コンセンサスに達したら、トップダウン型、ボトムアップ型、ハイブリッド型のどれを取るのが最善かを判断します。 正しいモデリング手法と適切な要素を一致させることで、モデリングを成功させる機会が劇的に増加します。 各種類のデータモデルには独自の長所と用途があるため、ビジネス利用ケースとその基盤技術に基づいてデータモデリング手法を選択します。
モデルを設計する際には、できるだけシンプルで実生活に近づけるようにしてください。 投機的なコンテンツを避ける - データモデルは要件を完全に満たしている必要がありますが、それらを過度にエンジニアリングする必要はありません。 すべてのチームと関係者間の縫い目のないオープンなコミュニケーションは、データモデリングの成功と、すべてのデータ要素が組み込まれ、組織全体で同じ意味と解釈を持つことを確実にする上で非常に重要です。
データモデルは、単一の問題を解決するように設計すべきではなく、エコシステムのすべてのデータ要素をより包括的な視点で捉え、さまざまな問題に対して設定する必要があります。 この手法では、効率的なデータモデルは、明確に定義されていない問題だけでなく、まだ説明されていない問題も解決することができます。
最後に、データモデルは生きた人工物であり、更新や保守を必要とするということを認識することが重要です。たとえば、データモデルのいかなるレベルに対して加えられた変更も、必ず他のレベルでも反映されるようにしなければならない、といったことです。 ほとんどのデータモデルでは保守はほとんど必要ないものの、モデルを最新の状態に保つための正式なプロセスがあることは重要です。
研究開発におけるデータモデリングの実際のアプリケーション
では、データモデルの設計は、実際はどのように動作するのでしょうか。 例として、家畜やペットフードの商品ラインを立ち上げた世界的な動物衛生会社を考えてみましょう。 この会社のデータモデルを作成するには、テキストコンテンツ、化学構造、薬物/ターゲット関係、分類動物名(界、門、属など)、財務値、回路図、グラフ、チャートやその他のすべての関連データ要素を考慮する必要があります。 これらの多面的なデートセットで、データモデルの複雑さを簡単に理解できます。
この様に複雑なR&Dケースの場合、データモデルが十分に詳細で役立つものでありながら容易く理解できるように、バランスを保つことが大切になります。 時間が経つにつれ、プロセスの変化による調整が必要になることもあるため、データモデルには柔軟性も考慮しなければなりません。
これらの必要性を考慮した場合、動物の栄養例の理論上のデータモデルは以下のようなものになります。
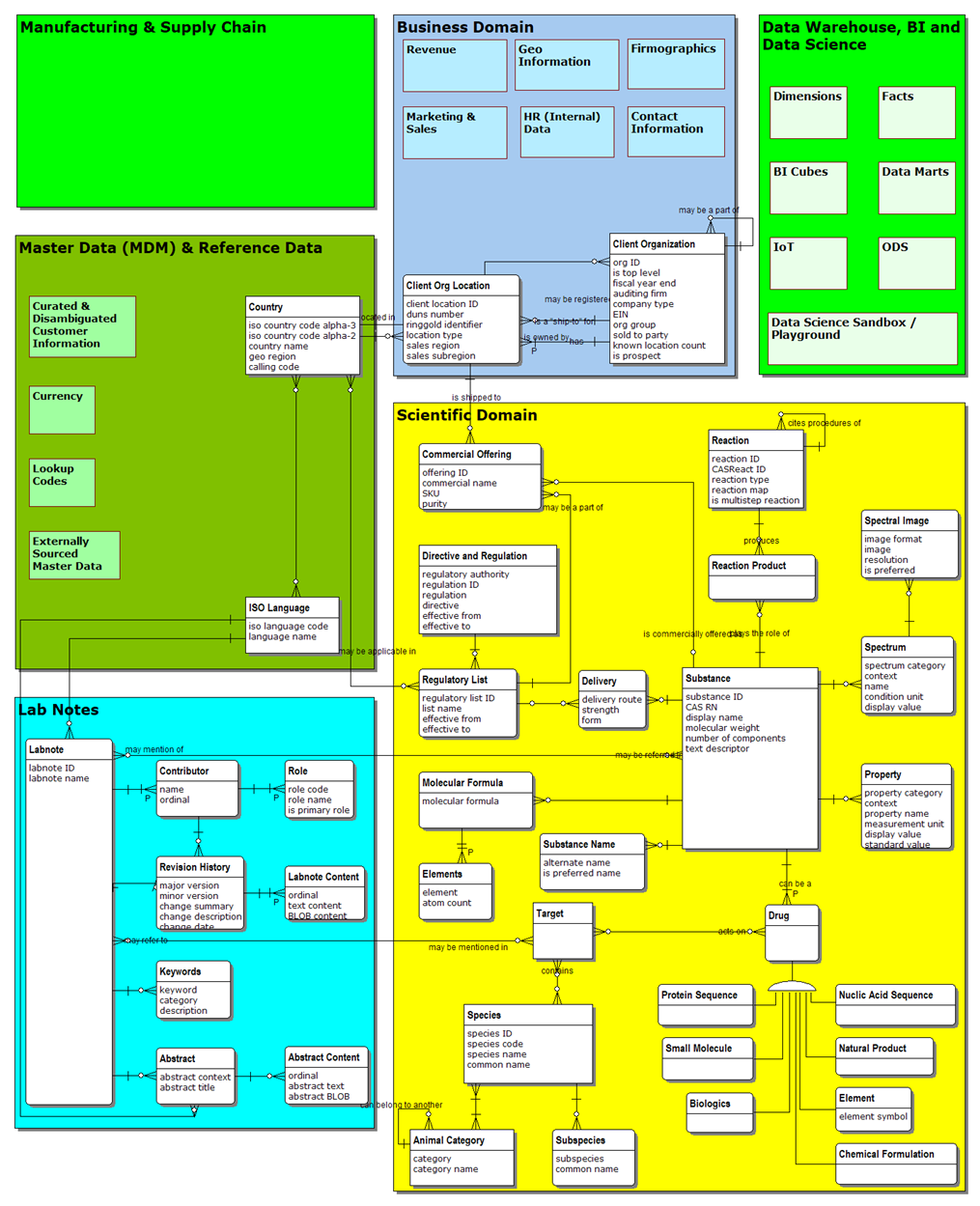
このモデルは、組織のデータを相互に結ぶため、データ要素と関係を標準的な方法で定義しています。 包括的な企業プロセスと報告を支援するため、モデルにビジネスとマスターデータを入れ込むことは特に重要です。 このデータモデルの例をより深く見ていくには、細かい詳細と考慮点が記載されている弊社のホワイトペーパーをお読みください。
将来のデジタル開発に向けて準備する
デジタル改革は超特急で行われており、データモデリングは今までにないほど影響力のあるものになっています。 そのため、R&Dの組織は、データモデリングを優先事項にして、自らのデータ資産の価値を最大限に活用することを目指すべきです。 データモデル設定に注いだ努力は、いずれ貴組織に競合上の優位性をもたらすソリューションを構築するための堅牢なデータ基盤を持った時に報われます。
データを正確に分類する企業データハブの構築をお考えで、より詳細な情報を希望されているなら、弊社による将来のデジタル機会のホワイトペーパーをダウンロードしてください。 その中で弊社は、データモデリングの重要性とR&Dのデジタル化の現状についてより詳しく検討しています。
