
Les Dark data en R&D : comment la gestion des connaissances permet de découvrir une valeur cachée
Les dark data sont définies par Gartner comme « les actifs d'information que les organisations collectent, traitent et stockent dans le cadre de leurs activités normales, mais qu'elles n'utilisent généralement pas à d'autres fins. » Dans la mesure où personne ne sait quelles données se trouvent là ni comment y accéder, les informations qu'elles contiennent restent cachées.
Les équipes de recherche et de développement (R&D) amassent d'énormes quantités de données complexes sur de longues périodes qui, si elles sont exploitées correctement, peuvent constituer une source abondante d'informations utiles pour améliorer la prise de décision et dynamiser l'innovation. Toutefois, les données risquent d'être cloisonnées dans de multiples systèmes de bases de données déconnectés, offrant peu de possibilités de recherche, ce qui rend extrêmement difficile et fastidieux l'accès aux éléments vraiment pertinents.
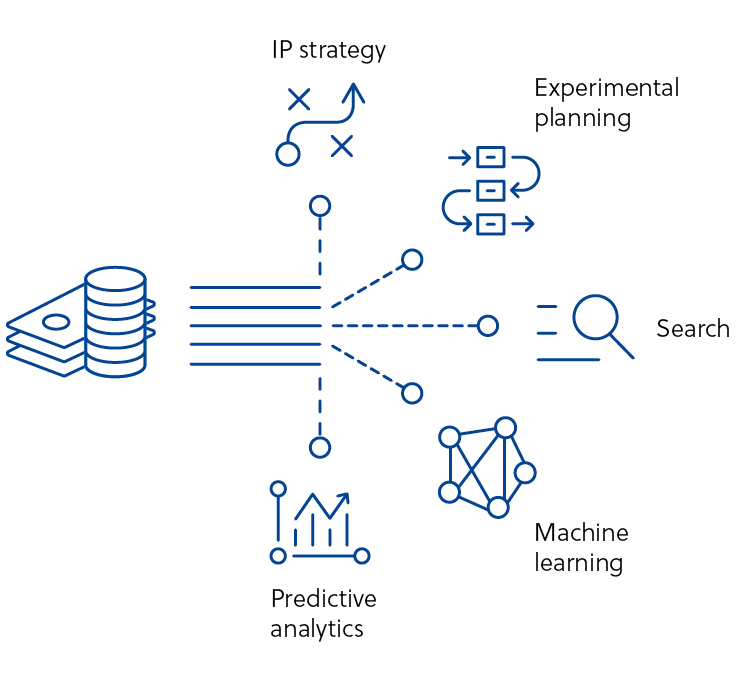
En effet, les propres données d'une entreprise peuvent être cachées à ses chercheurs, de sorte que des expériences peuvent être inutilement répétées, ce qui entraîne des pertes de temps et des dépenses. Outre la dissimulation des données, les systèmes actuels de gestion des données peuvent avoir du mal à connecter les données internes à des sources externes ; cela représente une opportunité manquée de générer une gestion des connaissances plus complète et exhaustive.
On estime que 55 pour cent des données stockées par les entreprises sont des données cachées, ou dark data. Pourtant, environ 90 pour cent des responsables et directeurs informatiques mondiaux reconnaissent que chaque entreprise devra extraire de la valeur de ces données non structurées pour réussir à l'avenir.
En termes clairs, si les informations continuent à être collectées, stockées et restent inutilisées, elles existent toujours en tant que dark data. Comment les entreprises peuvent-elles mettre en lumière leurs précieuses données de R&D ? Voici quelques moyens de découvrir leur potentiel caché :
1. Déterminer où se cachent les données de R&D les plus précieuses
Pour alléger le problème des données de R&D stockées dans des silos, une première étape cruciale consiste à déterminer quelles collections de données sont les plus précieuses pour favoriser la découverte ; il est impératif de permettre un accès intuitif aux résultats et découvertes expérimentaux aux personnes pertinentes dans toute l'entreprise.
Existe-t-il des connaissances dans la collecte desquelles les entreprises investissent du temps et des ressources, mais qui restent des dark data et ne sont pas réutilisés ultérieurement ? Lorsqu'ils sont mis en lumière, les résultats des données et de la recherche expérimentale passées peuvent guider des investissements avisés et éviter de répéter les mêmes expériences.
2. Rendre les données de R&D visibles grâce à des stratégies de gestion des connaissances
La gestion des connaissances en R&D doit non seulement tenir compte de la capture des informations, mais aussi inclure une gestion intentionnelle des données pour guider la prise de décision. Les entreprises ne peuvent réussir à convertir les données en connaissances utiles que si elles parviennent à les organiser de manière à ce qu'elles soient exploitables, connectées et facilement accessibles. Ces données ne seront peut-être pas utilisées constamment, mais doivent être trouvables lorsque cela est pertinent.
Pour bénéficier des informations dont elles disposent, les entreprises ont besoin des solutions et de l'expertise informatique adéquates pour créer des infrastructures de gestion des données afin d'organiser les données de R&D. Un défi courant auquel elles sont confrontées concerne l'harmonisation de la terminologie scientifique entre sources d'informations. Sans gestion d'un contexte scientifique cohérent, on risque de manquer des informations vitales au cours des recherches dans la base de données.
CAS utilise des lexiques spécialisés, des ontologies et des taxonomies associées à des technologies exclusives de comparaison des substances et à l'expertise de scientifiques pour standardiser le langage scientifique. Ainsi, les informations critiques dont les chercheurs ont besoin sont disponibles au bout de leurs doigts.
3. Récolter les bénéfices des données de R&D bien organisées et accessibles
Les données de R&D bien structurées et accessibles améliorent l'efficacité. Cela permet non seulement de gagner du temps dans la recherche des données requises, mais aussi d'éviter la répétition inutile des expériences et ainsi, d'économiser du temps et de l'argent. Un autre avantage majeur tient au fait que la prise de décision stratégique peut être accélérée et améliorée, ce qui aide l'entreprise à conserver son avantage concurrentiel.
CAS franchit un pas de plus au-delà de la simplification de l'identification des connaissances : il connecte aussi les informations, aussi bien en interne qu'avec la science mondiale. Cette étude de cas présentant une solution personnalisée de gestion des connaissances montre comment les documents d'une organisation peuvent être liés en toute sécurité et améliorés par CAS Collection de contenus TM ou même à des données organisées sur mesure provenant d'un secteur particulier, afin de rendre les données plus robustes. Les tendances, les collaborateurs et les concurrents peuvent être identifiés lorsque des concepts de recherche interne sont connectés à d'autres publications similaires et à des brevets du monde entier.
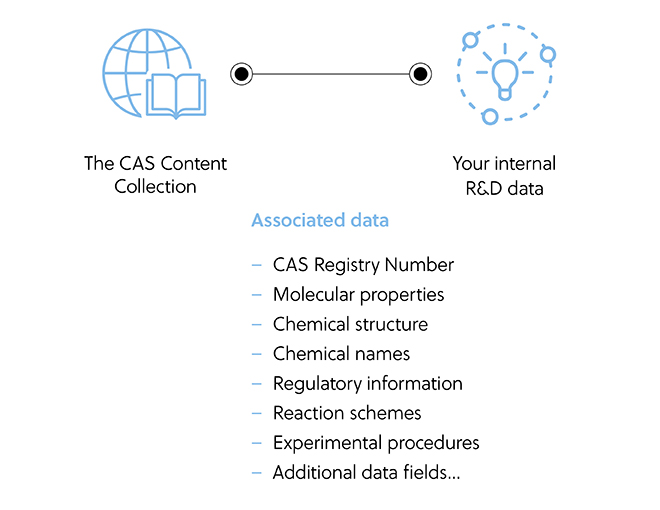
La conception de la gestion personnalisée des connaissances en action
CAS Services personnalisésSM crée des solutions pour stocker et connecter les données existantes dans un format structuré, ce qui permet à tous les employés d'accéder à des données de R&D précieuses de manière simple et efficace.
Découvrez exactement comment nos solutions peuvent vous être utiles.
Nous vous invitons à contacter CAS Services personnalisés pour discuter de la manière dont CAS peut répondre à vos besoins uniques de gestion des connaissances.
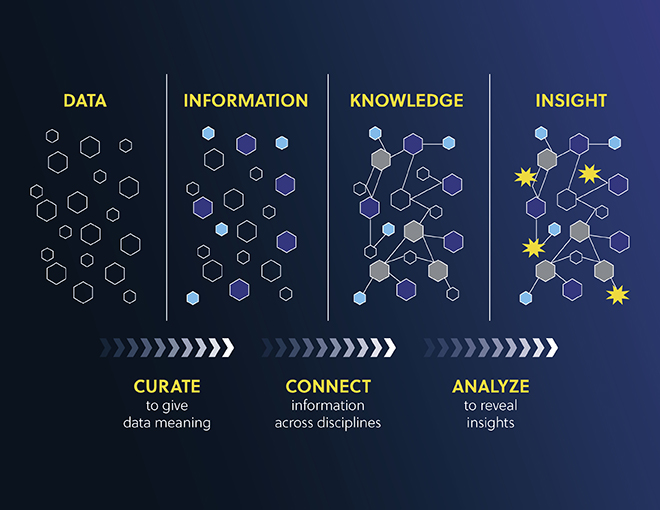
CAS révèle tout le potentiel des actifs numériques d'une entreprise avec des processus similaires à celui qu'il utilise pour organiser les données scientifiques publiées dans le monde entier. Nos solutions de gestion des connaissances vont au-delà de la recherche par mot clé et permettent d'accéder à un contexte scientifique. En organisant, en connectant et en analysant des documents internes, les entreprises peuvent effectuer des recherches dans l'intégralité du texte de documents autrefois cachés, connecter les concepts similaires et procéder à des recherches par concepts adaptés à leur orientation de découverte spécifique.
La mise en relation des données d'une organisation avec la science mondiale permet d'améliorer la prise de décision, d'accélérer l'innovation et de rehausser la valeur de vos données.
Découvrez comment nos solutions d'informations innovantes ont guidé la recherche dans une grande organisation de technologies de la santé. Pour en savoir plus, téléchargez notre étude de cas, « Libérer le potentiel des données de R&D : Organiser et connecter les données pour obtenir des informations exploitables ».