Gain new perspectives for faster progress directly to your inbox.

Dark data in R&D: How knowledge management can uncover hidden value
Dark data is defined by Gartner as “the information assets organizations collect, process, and store during regular business activities, but generally fail to use for other purposes.” As no one knows what data is there or how to access it, the insights it contains remain in the dark.
Research and development (R&D) teams amass huge quantities of complex data over long periods of time which, if exploited correctly, can be a plentiful source of useful information to improve decision-making and drive innovation. However, data can become compartmentalized in multiple disconnected database systems with limited ability to be searched, which makes accessing the truly relevant parts extremely difficult and time-consuming.
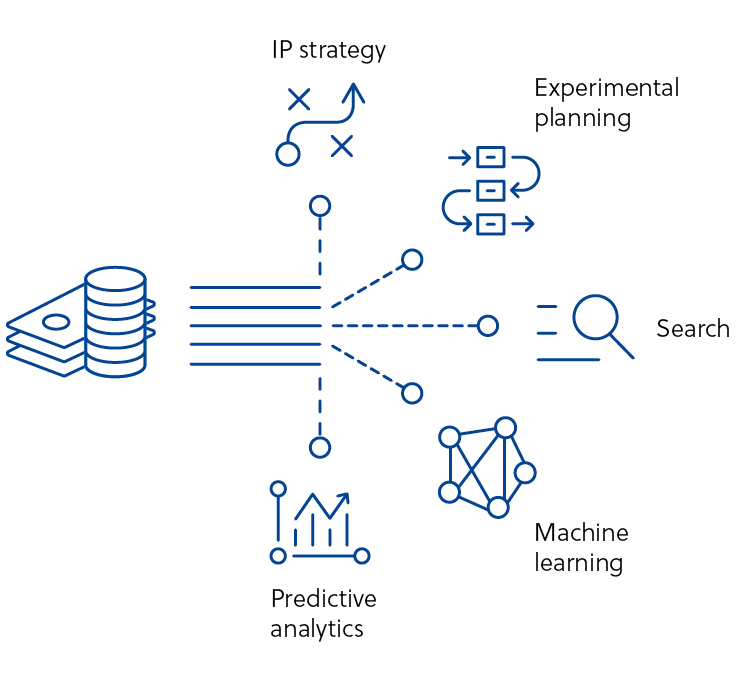
In effect, a company’s own data can be hidden from its researchers, meaning that experiments might be unnecessarily repeated leading to time and cost implications. Alongside concealing data, current data management systems can struggle to connect internal data with external sources; this is a missed opportunity for generating more comprehensive and complete knowledge management.
It is estimated that 55 percent of data stored by organizations is dark data. Yet, around 90 percent of global business and IT executives and managers agree that every organization will need to extract value from this unstructured data to be successful in the future.
Put simply, if information continues to be collected, stored, and left unused, it will continue to exist as dark data. So how can organizations shine a light on their valuable R&D data? Here are a few ways to uncover its hidden potential:
1. Determining where the most valuable R&D data is hiding
To alleviate the barrier of R&D data sitting in silos, a crucial first step is to determine which data collections are most valuable to enable discoverability; it is imperative to enable intuitive access to experimental results and findings to relevant individuals across the organization.
Is there knowledge that organizations are investing time and resources collecting, but is kept as dark data without future re-use? When brought to light, past experimental data and research findings can guide wise investments and prevent repeating experiments.
2. Making R&D data visible through knowledge management strategies
Knowledge management in R&D must not only consider capturing information, but also include intentional data management to guide decision-making. Organizations can only succeed in converting data into useful knowledge if they can successfully organize it in a way that is searchable, connected, and easy to access. The data may not be used all the time, but it needs to be findable when relevant.
To take advantage of the insights they own, organizations need the right IT solutions and expertise to create data management frameworks to organize R&D data. One common challenge faced is harmonizing scientific terminology across information sources. Without maintaining consistent scientific context, vital information can be missed during database searches.
CAS uses specialized lexicons, ontologies, and taxonomies paired with proprietary substance comparison technologies and expertise of scientists to standardize scientific language. This ensures critical information researchers need is at their fingertips.
3. Reaping the benefits of well-organized and accessible R&D data
Well-structured and readily accessible R&D data improves efficiency. Not only is time saved on searching for the required data, but unnecessary repetition of experiments can be avoided leading to time and cost savings. Another major benefit is that strategic decision-making can be accelerated and improved, helping an organization maintain a competitive edge.
CAS goes one step further than simply finding data – they also connect information internally and to the world’s science. This case study featuring a custom knowledge management solution shows how an organization’s documents can be securely linked to and augmented by the CAS Content CollectionTMor even to custom-curated data from a particular industry to make internal data more robust. Trends, collaborators, and competitors can be identified when concepts in internal research are connected other similar publications and patents from around the world.
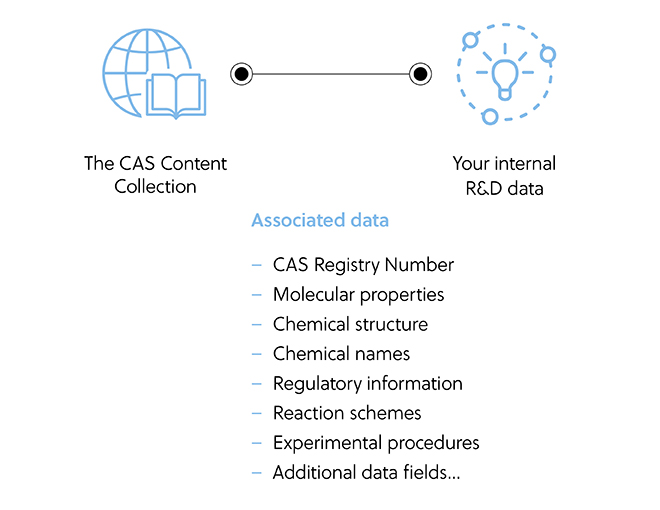
Custom knowledge management design in action
CAS Custom ServicesSM builds solutions for storing and connecting existing data in a structured format, allowing all employees to access valuable R&D data in a straightforward and efficient manner.
Find out exactly how our solutions can benefit you.
We invite you to contact CAS Custom Services to discuss how CAS can meet your unique knowledge management needs.
CAS reveals the full potential of an organization’s digital assets with similar processes to the one it uses to curate the world’s published science. Our knowledge management solutions move beyond standard keyword search and enable scientific context. By curating, connecting, and analyzing internal documents, organizations can search the full text of once-hidden documents, connect similar concepts and substances, and search by concepts tailored to their specific discovery focus.
Connecting an organization’s data to the world’s science allows for improved decision- making, faster innovation, and makes your data more valuable.
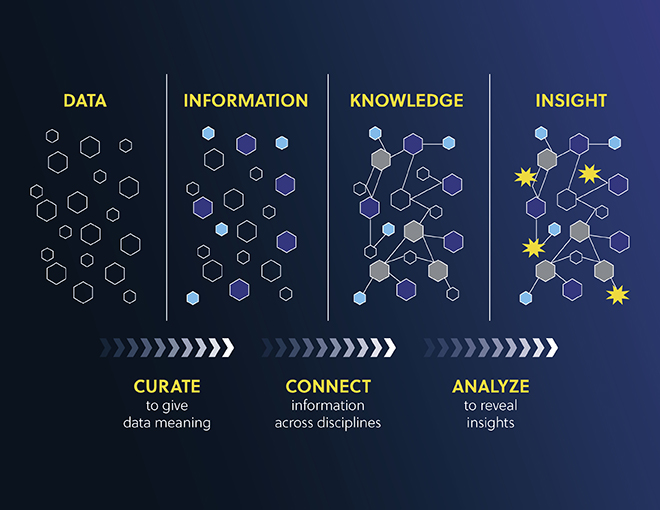
See how our innovative information solutions have driven discovery in a large health-tech organization. Learn more by downloading our case study, “Unravel the potential of internal R&D data: Curate and connect for searchable insights”.